

Ondanks het anoniem maken van de gesproken namen door Dragon Medisch, behoudt Dragon een goede leercurve met handhaving van security. Hoe doet Nuance dat?
Privacy is enorm belangrijk vooral in de medische wereld. Voor optimalisatie van de herkenning voor spraak-naar-tekst worden alle woorden, zinsdelen en zinnen opgeslagen met daarbij de audio per auteur.
Voor de privacy van de persoonsgegevens is essentieel dat deze gevoelige informatie uit de tekst wordt verwijderd. Namen, datums en soortgelijke categorieën worden verwijderd na omzetting van S2T.
De tekst met audio wordt anoniem opgeslagen om op een later tijdstip deze informatie te analyseren en de herkenbaarheid hiermee te verbeteren.
Voor het Dragon-gebruik betekent dit het verwijderen van in wezen alle namen van patiënten en zorgverleners, een groot deel van de datums en in het algemeen een aanzienlijk aantal nummers, eigennamen van organisaties en plaatsen, en nog veel meer.
Nadeel van deze methode is dat de herkenbaarheid 50 % tot 90 % slechter is dan wanneer deze informatie wel zou worden gebruikt. Nuance heeft dit opgelost door willekeurige namen op de anonieme plaatsen in een regel te plaatsen.
Voor machine learning, de methode die Dragon hanteert om de hoge herkenbaarheid te krijgen, is kwantitatief en kwalitatief erg belangrijk.

Figuur 1 ⬆ toont de workflow van deze methode. Het verzamelen van trainingsgegevens begint met het opnemen van gesprekken. De audio-opname wordt vervolgens getranscribeerd en persoonlijk identificeerbare informatie (PII) wordt geannoteerd. Voor deze PII-reeksen wordt zogenaamde surrogaattekst gegenereerd: willekeurige vervangingen, bijv. "John" kan worden vervangen door "Michael".
Vervolgens wordt tijdens de de-identificatie PII-tekst vervangen door surrogaattekst en wordt de bijbehorende audio verwijderd. Ten slotte wordt audio die overeenkomt met de surrogaattekst gegenereerd met behulp van verschillende methoden die hieronder worden uitgelegd, en de nieuwe audio/transcriptieparen inclusief surrogaten worden gebruikt voor modeltraining in plaats van het originele materiaal.
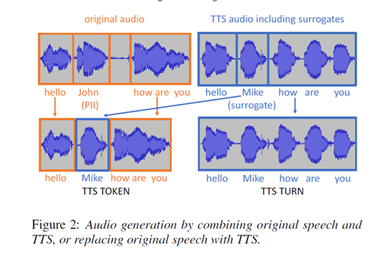
De eerste methode om audio voor de surrogaattekst te genereren, is gebaseerd op tekst-naar-spraaktechnologie (TTS). Een TTS-systeem is een machine learning-model dat is getraind om audio-uitvoer te vervaardigen voor tekstinvoer (en metadata, bijvoorbeeld die de kenmerken van de gewenste stem beschrijven).

Als we audio nodig hebben voor de surrogaattekst "Mike", dan zoeken we in onze gegevens naar elk voorkomen van Mike en kunnen we de uitspraak "tot ziens Mike" vinden. Vervolgens knippen we het audiofragment "Mike" uit en splitsen het met omringende elementen van de originele audio.
Conclusie:
Concluderend: de-identificatie is een bijzondere uitdaging voor end-to-end automatische spraakherkenning. Met behulp van de bovengenoemde methode kan het verlies in algemene prestaties worden hersteld. Het belangrijkste is dat tussen 50% - 90% van de herkenningsnauwkeurigheidsdaling voor categorieën zoals namen of datums ook kan worden hersteld. En dat de security aangaande persoonsgegevens is gedekt.
Anonimisering is niet hetzelfde als Pseudonimisering. Bij anonimisering is de data volkomen vrij van gegevens.
Pseudonimisering worden de gegevens zo aangepast dat het niet te achterhalen is waar de gegevens vandaan komen maar
blijven in principe wel persoonsgegevens.









